As part of a larger project, MehDB, I developed multiple implementations of a striped locking mechanism in both Rust and Golang (blog post on that soon?).
While limited in application, striped locks are an effective way to manage more resources than can effectively fit in memory while supporting a high degree of parallelism. One way to implement a striped lock is with a simple hash map that eschews collision handling and an array of Mutexes.
Here is a naive implementation in Golang:
type Lock interface { sync.RWMutex | sync.Mutex } type StripedMutex[T Lock] struct { locks []T } func New[T Lock](numlocks uint) StripedMutex[T] { return StripedMutex[T]{ locks: make([]T, numlocks), } } func (l *StripedMutex[T]) Get(i int) *T { return &l.locks[i%len(l.locks)] }
Now, before you go copy-pasting this, there are some significant performance improvements to be had that are a bit subtle. We'll get to that soon.
Some other things to note: your data may not always be identifiable with just an int, for example, a UUID or string might be used as the unique ID. In my case, I already have run my resource identifier through a high-quality hash function such as Highway Hash or xxHash to get a digest, which makes this easy.
As you can see, this is like an incredibly naïve hash map implementation, simply taking the input identifier modulo the total number of locks, and returning the corresponding lock. There is no attempt to handle conflicts. Keys that would otherwise conflict behave as if they are the same resource. In practice, this means you can make space vs parallelism tradeoffs by increasing the number of locks along with the number of simultaneous processes.
One very important thing here is that the total number of locks does not equate to that many parallel processes in all scenarios, it depends on the "spread" of the keys you use to address the locks. This means you probably want to use a hashing function, even if you can identify your resource using plain integer keys, and allocate more locks than your expected parallelism. I typically opt for 50% more locks than threads and have seen good performance, but YMMV. As always, the best decisions are made with your specific situation in mind.
So how about those performance improvements I was talking about before? Well, an important thing when dealing with high-performance applications is being aware of the CPU caching architecture. Most CPUs employ at least an L1 cache and most modern multi-core processors will have L1-L3 with varying size and latencies, with L3 typically being shared across all cores on the machine. When trying to maximize parallelism and throughput, we want to minimize how often these cores need to trigger a sync between their non-shared caches. Much like the unit of a CPU is the register, the unit of the CPU cache is the cacheline. On most modern systems, the cacheline size is 64 bytes.
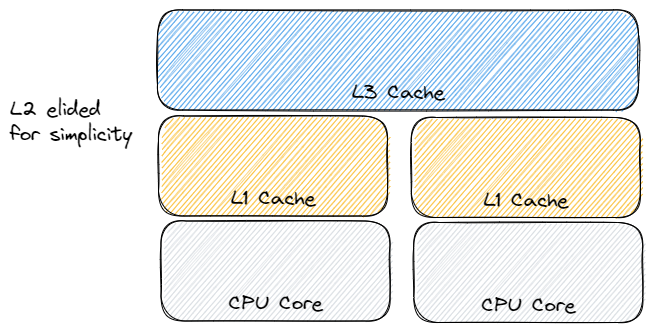
Why is this important? Well, a Mutex in Golang is exactly 8 bytes. 8 of them can fit into a single cacheline if they're perfectly aligned. If left as it is, the implementation above will have to sync their caches as each core modifies (ie. calls Lock()) the Mutex.
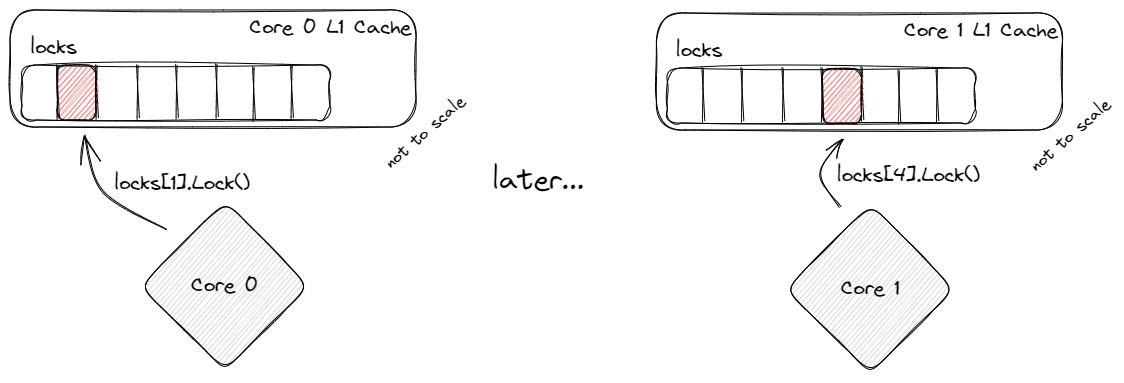
Let's say we have 2 cores and 8 locks aligned to the CPUs cacheline. Core 0 locks the Mutex at index 1, which modifies some internal properties of the lock. This is fast, as the cacheline has not been modified and Core 0 has exclusive write access to the area of memory that stores locks. It acquires the lock and moves onto whatever it needs to do next.
Meanwhile, Core 1 acquires the lock at index 4. However this time, the cacheline holding the locks has been marked as "dirty" by Core 0, so we must sync the cacheline before we can read or write to it. Doing this is comparatively slow. To make matters worse, every Lock() or Unlock() call modifies the Mutex and therefore the cacheline, doubling the contention per mutex per core even though the resources are not actually shared and require synchronization between cores. This is referred to as "false sharing", that is: when the CPU cores must synchronize despite accessing disparate resources due to properties of the hardware.
Fortunately, this has a pretty simple solution.
import ( "sync" "golang.org/x/sys/cpu" ) type Lock interface { sync.RWMutex | sync.Mutex } type StripedRecord[T Lock] struct { lock T _ cpu.CacheLinePad } type StripedMutex[T Lock] struct { locks []StripedRecord[T] } func New[T Lock](numlocks uint) StripedMutex[T] { return StripedMutex[T]{ locks: make([]StripedRecord[T], numlocks), } } func (l *StripedMutex[T]) Get(i int) *T { return &l.locks[i%len(l.locks)].lock }
We create a new struct to hold the T generic type and add an unnamed variable that is of type cpu.CacheLinePad, which is a architecture-specific sized byte array. This makes sure that each lock is on it's own cacheline, meaning cores only need to sync when they are accessing the same lock.
Here is some quick benchmarking code:
import ( "runtime" "sync" "testing" ) func BenchmarkStripedMutex(b *testing.B) { procs := runtime.GOMAXPROCS(0) lock := New[sync.Mutex](uint(procs)) threadMut := sync.Mutex{} threadId := 0 b.RunParallel(func(pb *testing.PB) { threadMut.Lock() id := threadId threadId++ threadMut.Unlock() for pb.Next() { lock.Get(id).Lock() lock.Get(id).Unlock() } }) }
The results without the cpu.CacheLinePad:
goos: linux
goarch: amd64
pkg: git.sr.ht/~chiefnoah/mehgo/pkg/locks
cpu: AMD Ryzen 9 7900X3D 12-Core Processor
BenchmarkStripedMutex-24 1000000000 5.967 ns/op
And the results with the padding:
goos: linux
goarch: amd64
pkg: git.sr.ht/~chiefnoah/mehgo/pkg/locks
cpu: AMD Ryzen 9 7900X3D 12-Core Processor
BenchmarkStripedMutex-24 1000000000 0.2572 ns/op
Each iteration speeds up about 23x with the padding!
The code for this can be found here, as part of my rewrite of MehDB in Golang.